India
Data from the Reserve Bank of India's Handbook of Statistics on Indian States.
MAPWise: Evaluating Vision-Language Models for Advanced Map Queries
MAPWise is a novel benchmark designed to evaluate the performance of Vision-Language Models (VLMs) in answering map-based questions. Choropleth maps, commonly used for geographical data representation, pose unique challenges for VLMs due to their reliance on color variations to encode information. Our study introduces a dataset featuring maps from the United States, India, and China, with 1000 manually created question-answer pairs per region. The dataset includes a diverse set of question templates to test spatial reasoning, numerical comprehension, and pattern recognition. Our goal is to push the boundaries of VLM capabilities in handling complex map-based reasoning tasks.
TL;DR: MAPWise is a benchmark designed to evaluate Vision-Language Models (VLMs) on map-based questions. It includes 3,000 manually curated Q&A pairs across maps from the United States, India, and China, testing spatial reasoning, numerical comprehension, and pattern recognition.
India
Data from the Reserve Bank of India's Handbook of Statistics on Indian States.
USA
Healthcare statistics from the Kaiser Family Foundation.
China
Socioeconomic data from the National Bureau of Statistics of China.
Defined categorical legend with clear boundaries.
Gradual spectrum-based legends.
Maps with labels to aid interpretation.
Alternative representations using texture.
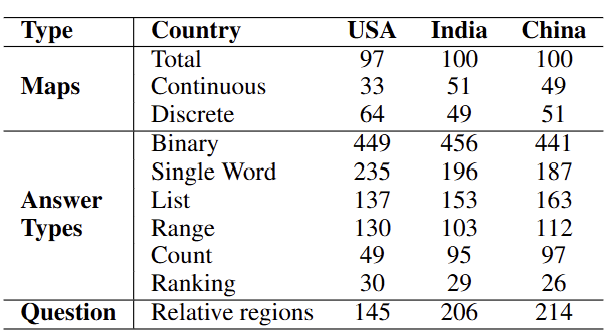
To design a Robust Benchmark for Map-Based QA, we developed question templates that vary in difficulty, from simple yes/no questions to complex region association tasks requiring spatial reasoning. The dataset includes three primary question types: Binary questions that require a yes or no answer based on map features, Direct Value Extraction tasks that involve retrieving specific numerical or categorical values from maps, and Region Association questions that challenge models to identify or count regions meeting particular criteria, often requiring geospatial reasoning.
To ensure high dataset quality, expert annotators meticulously reviewed all questions and answers. A rigorous benchmarking process, including human evaluation, was conducted to assess dataset reliability. This evaluation highlights the limitations of existing Vision-Language Models (VLMs) in handling complex map-based reasoning tasks and provides valuable insights for future improvements.
| Answer Type | Example Question |
|---|---|
| Binary | Yes or no: California is an outlier compared to its neighbors? |
| Single Word | Name the eastern-most state that belongs to a higher value range compared to all its neighbors. |
| List | Which states in the East China Sea region have a value higher than state Guangdong? |
| Range | What is the least value range in the west coast region? |
| Count | How many states bordering Canada have a value lower than New Mexico? |
| Ranking | Rank Rajasthan, Gujarat, and Jammu & Kashmir in terms of the legend value in the region bordering Pakistan. |
We evaluated multiple Vision-Language Models (VLMs) on the MAPWise dataset. The models included both closed-source and open-source multimodal models:
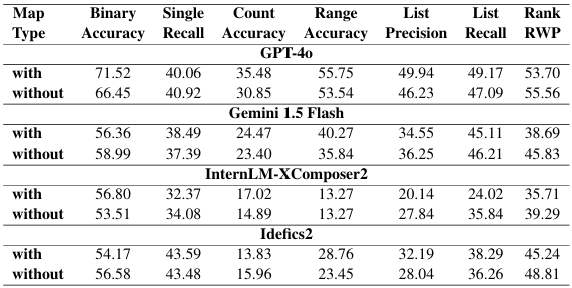
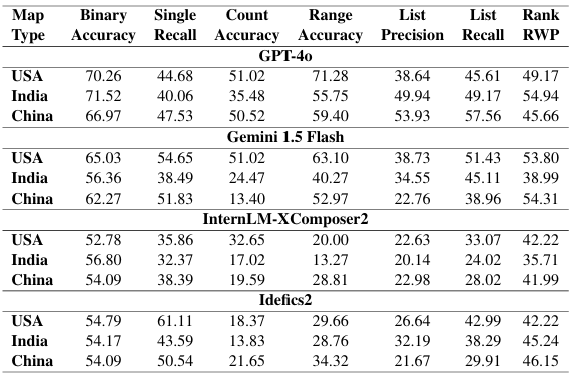
We conducted thorough Analysis to evaluate closed-source model performance, the effectiveness of different prompting strategies, and biases in model predictions. The study examined how models performed across different map types (discrete vs. continuous, colored vs. hatched), annotations (with vs. without labels), and country-wise variations. Additionally, model accuracy was compared across various question-answer types, revealing significant gaps in spatial and numerical reasoning. For Complete Results, Please visit Appendix in Paper
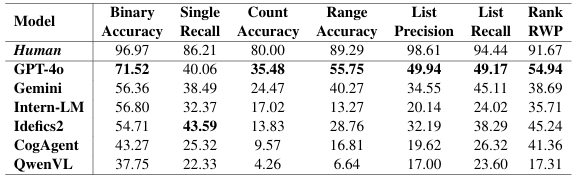
The MAPWise dataset reveals a significant performance gap between current Vision-Language Models (VLMs) and human performance, especially on complex reasoning tasks (e.g., counting, listing). Existing VLMs have substantial limitations in reasoning abilities, highlighting the need for further research. The average gap is close to 50% on some task types.
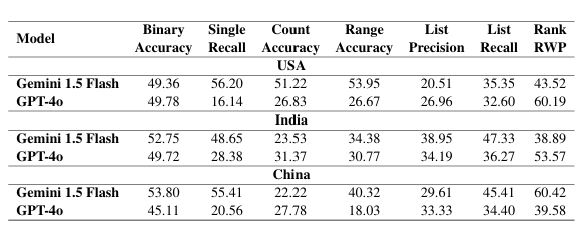
GPT-4o consistently outperforms other models, followed by Gemini 1.5 Flash. Gemini excels with hatched maps due to better legend resolution, while GPT-4o is generally better due to stronger reasoning. Open-source models (Idefics2, InternLM) show promise but struggle with complex reasoning, particularly evident in QwenVL's low counting accuracy (4.26%). Both strong data extraction and sophisticated reasoning are crucial for geo-spatial understanding.
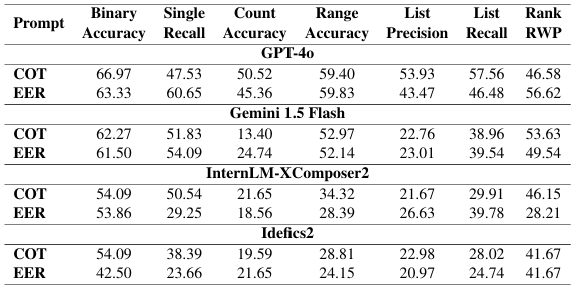
Standard Chain-of-Thought (COT) prompting generally outperforms Explicit Extraction and Reasoning (EER), except for Gemini 1.5 Flash, which performs similarly with both. Gemini 1.5 Flash has strong instruction-following capabilities. Larger models implicitly use an EER-like approach, showing progress in reasoning. Smaller models struggle with EER's complexity.
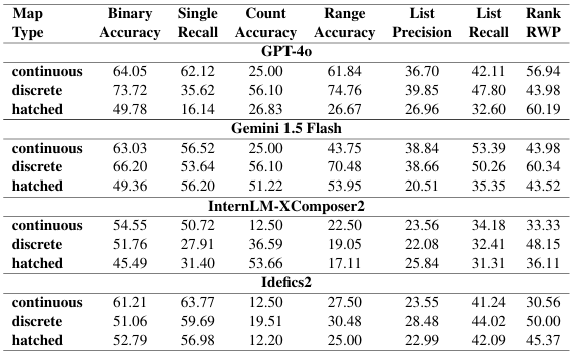
Models generally perform better on discrete maps than continuous maps, especially for counting and range extraction. Continuous maps pose challenges in legend range and color resolution. Models do better on single-word answers within the continuous category, possibly due to question simplicity.
Models consistently perform better on colored maps than hatched maps, indicating a preference for colored data representation. Even GPT-4o shows significant performance drops on hatched maps. Idefics2 is the most robust to this map type.
Models perform similarly on maps with and without annotations. Sometimes, performance is *better* without annotations. Annotations are not a crucial factor for model performance in map understanding, though they can sometimes be beneficial.
Open-source models show consistent performance across countries (USA, India, China), while closed-source models exhibit greater variation. Potential training data biases may contribute to performance differences in closed-source models across different geographic regions.
Models excel at binary questions, followed by single-word answers (strong data extraction). Closed-source models do well on range questions. Counting and listing tasks are the most difficult, requiring complex reasoning, external knowledge, and geospatial understanding. These are challenging even for humans. Models struggle with most questions concerning relative regions, except for binary questions.
Some models (CogAgent, QwenVL) perform below random baselines on binary questions and list precision. This is due to irrelevant responses, repeated tokens, failure to generate valid responses, poor data processing, hallucination, and a lack of task comprehension. Examples show failures in value deduction and task understanding.
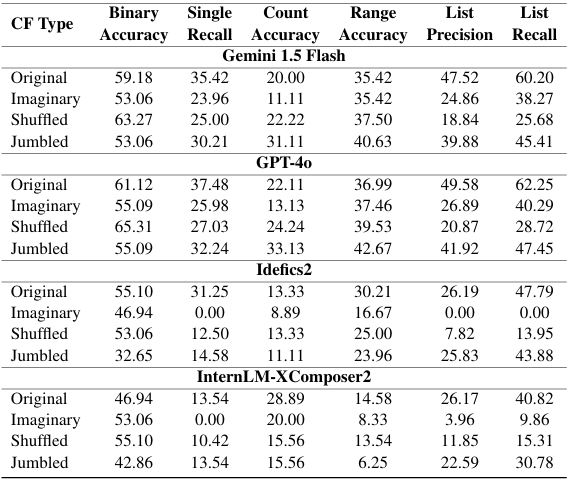
To analyze how models rely on internal knowledge versus actual map interpretation, we designed three types of counterfactual datasets. These datasets forced models to focus exclusively on the provided maps by altering the textual or numerical elements. For Results of Additional Model, Please visit Appendix in Paper
To establish a baseline, we conducted a human evaluation of the MAPWise dataset. The evaluation included 450 randomly selected questions spanning three countries: USA, India, and China. These questions were answered by three independent human annotators with expertise in map interpretation and spatial reasoning. The annotators followed a majority voting system to determine the final answers. The dataset included both discrete and continuous maps, covering various answer types such as binary, list, ranking, and count-based questions.
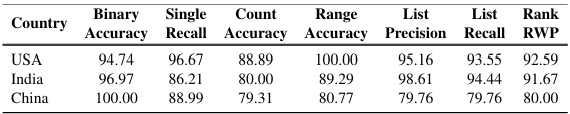
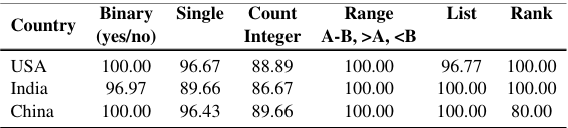
Human evaluators consistently outperformed all Vision-Language Models (VLMs), particularly in reasoning-heavy tasks such as ranking and list-based questions. While human accuracy for binary and direct extraction tasks was near-perfect (above 95%), models struggled significantly, with even the best-performing model (GPT-4o) achieving only 71.52% binary accuracy and much lower recall on list-based questions.
This stark contrast underscores the challenges faced by VLMs in tasks requiring advanced spatial and numerical reasoning. Despite their sophisticated architectures, models exhibited biases, hallucinations, and errors when extracting values from the legend. The significant performance gap between humans and models highlights the need for advancements in multimodal learning techniques and improved reasoning strategies to bridge this divide.
We are grateful to Arqam Patel, Nirupama Ratna, and Jay Gala for their help with the creation of the MAPWise dataset. Their early efforts were instrumental in guiding the development of this research. We also thank Adnan Qidwai and Jennifer Sheffield for their valuable insights, which helped improve our work. We extend our sincere thanks to the reviewers for their insightful comments and suggestions, which have greatly enhanced the quality of this manuscript.
This research was partially supported by ONR Contract N00014-23-1-2364, and sponsored by the Army Research Office under Grant Number W911NF-20-1-0080. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
The MAPWise dataset is prepared by the following people:






@misc{mukhopadhyay2024mapwiseevaluatingvisionlanguagemodels,
title={MAPWise: Evaluating Vision-Language Models for Advanced Map Queries},
author={Srija Mukhopadhyay and Abhishek Rajgaria and Prerana Khatiwada and Vivek Gupta and Dan Roth},
year={2024},
eprint={2409.00255},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2409.00255},
}